用 Java 把一个文件夹下的文件随机分为 x 份 x = 总份数 / n
以下内容由 chatGPT,一次生成而来,强大且高效,直接跑过,记录下,下次直接用

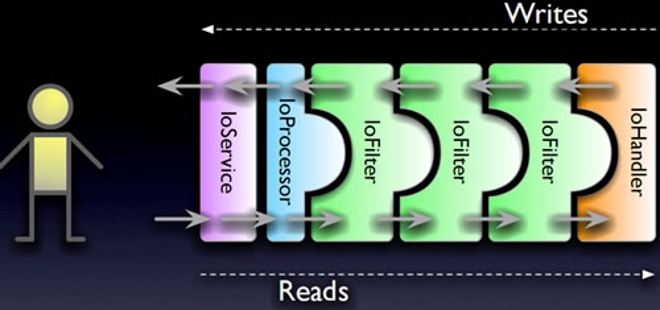
最近在 学习了socket 发现socket果然是个好东西. 仔细的去了解发现用途真的太多.通过scoket编写的东西能很好的做到各种兼容性.比如大家孰知的HTTP 协议了.sokcet通过一些同行协议就能就完成了HTTP . 想想就感觉好厉害呀.
HTTP 这样强大的协议也不是在任何情况都是很有效的.如HTTP 需要实现长链接就显得有些力不从心了.HTTP 适合BS下的应用需要什么数据就从服务器请求什么数据.如果想要服务器主动找客户端的话就不是那样容易了.HTTP 基于请求的特点就无法完成服务端一主动找客户端(浏览器)
人难免会忘记 。 有时候少打个: 也要纠结半天
mysql --> jdbc:mysql://localhost:3306/blog[?useUnicode=true&characterEncoding=UTF-8&user=blog&password=xxxxx] ?useUnicode=true&characterEncoding=UTF-8 可以避免一些应为mysql 安装时没有设置编码 带来的问题。 就这个有点想个网址 其他 oracle 的: sqlserver的 ; 还真给带来不少的疑惑
sql server --> jdbc:sqlserver://localhost:1433;databasename=jblog
sqlite --> jdbc:sqlite:/E:/1.db
oracle --> jdbc:oracle:thin:@localhost:1521:orcl
目前 接触过这4个数据库。
JDBC 是个好东西。
byte b[] = new byte[1] ;
这个可以避免文件经过处理后文件变大的问题。 但是处理大文件时显得就相当吃力了。
于是new byte[1] 不是一个好的选择。
byte b[]=new byte[new File("E:/1.iso").length];
这个可以提高速度。 但是带来又一个问题就是。 这个一次性把文件写到缓存区。 对与小文件没有问题。 但是大文件。 恐怕就........
于是就想到了。我有针对的出来最后一次流的大小不就行了。
贴代码开始
public static void moveOrCopyFile(String src,String tag,boolean isMove){
try {
long s=System.currentTimeMillis();
File f=new File(src);
FileInputStream in=new FileInputStream(src);
int fileSize=(int) f.length();
byte b[]=null;
new File(tag).createNewFile();
FileOutputStream out=new FileOutputStream(tag);
int cnt=fileSize/(1024*1024);
//小于1M(大小根据自己的情况而定)的文件直接一次性写入。
if(cnt==0)
{
b=new byte[fileSize];
}
else
{
b=new byte[1024*1024];
// 出来cnt次后 文件 跳出循环
while(in.read(b)!=-1)
{
out.write(b);
if(--cnt==0)
{
break;
}
b=new byte[1024*1024];
}
//最后一次流的大小通过取模的方式得到
b=new byte[fileSize%(1024*1024)];
}
//最后一次的文件写入
in.read(b);
out.write(b);
// 一定要记得关闭流额。 不然其他程序那个文件无法进行操作
in.close();
out.close();
System.out.println(System.currentTimeMillis()-s);
if(isMove)
{
f.delete();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//System.out.println(src);
//System.out.println(tag);
}
外面递归移动或者拷贝文件的方法就不演示了。